
약 7개월 전 엔비디아는 테슬라 V100, 즉 만 불짜리 볼타 GV100 GPU를
슈퍼컴퓨팅과 고성능 컴퓨터시장에 출시했다.
이 거대한 카드는 거대한 다이 사이즈(815 mm sq)와 엄청난 수의 트랜지스터 (21.1B)때문에
전문화된 시장을 목표로 잡았다.
게다가 전문화된 텐서 코어와, 16기가바이트의 2세대 고대역폭 메모리
그리고 엔비디아가 전에 내놓은 어떠한 것보다 일처리에 있어서 훨씬 뛰어난 이론적 성능을 제공한다.
오늘 신경정보처리시스템(NIPS)에 관한 회의에서
젠슨황은 기습적으로 전통적인 GPU 폼 팩터를 갖고 있는 똑같은 GV100 구조를 발표했다.
마치 GTX1080 Ti가 엔비디아 타이탄 Xp의 성능을 약간 다운시킨 버전인 것과 마찬가지로
이 번의 새로운 타이탄 V는 몇몇 점에서 완전체 뚱뚱한 테슬라 V100과 비교하면 몇몇 구성이 날씬해졌다.
메모리 클럭은 아주 조금 줄어들었다.(1.75Gbps에서 1.7Gbps의 전송속도로)
그리고 GPU는 3072비트에 3개의 메모리 채널인데 테슬라 V100이 갖고 있는 4096비트보다는 적다.
또한 2세대 고대역폭메모리는 단지 12GB만 갖고 있다. 이것은 테슬라 V100의 16GB보다 적다.
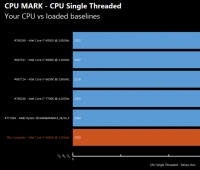
엔비디아는 타이탄 V가 110TFLOPS의 성능을 제공한다고 자랑하고 있다.
전 세대보다 9배 높은 수치이다. 우리는 글자 그대로 사실임을 의심하지 않는다.
그러나 이 비교는 우리가 보통 GPU FLOPS 성능을 말할 때 참고하는
단일 정밀도 또는 2배 정밀도에 대한 것이 아니다.
이 비교는 딥 러닝 작업에 있어서 파스칼에 대한 볼타의 성능향상을 비교 참조한 것이다.
그리고 파스칼의 32비트 단일 정밀도 처리량에 비교해 볼 때
(전문화된 텐서 코어들) 볼타 텐서의 성능을 비교함으로써 얻어진 것들이다.
그렇다고 해서 이 비교가 무효화되는 것은 아니다.
볼타는 파스칼이 가지지 못한 신경망훈련을 위한 전문화된 텐서 코어를 가지고 있기 때문이다.
그러나 한 CPU의 AES 암호화 성능을 그 성능이 없는 다른 CPU와 비교하는 것과 좀 비슷하다.
비교는 공정한 것인가? 절대로 그렇다. 그러나 측정되는 특정한 기준에서만 공정하다.
한 CPU가 다른 CPU에 대한 성능향상의 비율을 측정하는 일반화된 실험 케이스와는 반대된다.
엔비디아의 타이탄 V의 목표는 수퍼컴퓨터나 커다란 철제 고성능 컴퓨터 시설에 접근하지 못하는 연구원에게
동료들이 즐길 수 있는 최상의 하드웨어 성능에 접근하게 하는 것이다.
GPU가 눈이 똥그라질정도의 가격인 3천불이더라도 (보통 PC 시장에 상대적으로)
이 가격은 고성능 컴퓨터 서버의 보통 가격에 비한다면 그리 많은 것이 아니다.
“볼타에 대한 우리의 미래 비전은 고성능 컴퓨터와 인공지능의 한계를 밀고 나가는 것이다.
우리는 새로운 프로세서 구조,명령어들,숫자의 포맷,기억장치 구조와 프로세서 연결에 새로운 개척을 했다.”라고
엔비디아 CEO인 젠슨 황이 말했다.
타이탄 V로 우리는 볼타를 전세계에 있는 연구자와 과학자들 손에 쥐어주게 되었다.
나는 곧 그들의 돌파구적인 발견을 보게 될 것이다.
당신은 엔비디아 가게에서 바로 지금 타이탄 V를 살 수 있습니다.
그러나 우리는 이 분야에서 일하고 있지 않는 분에게는 솔직하게 말해 추천해 드릴 수는 없습니다.
타이탄이라는 브랜드는
처음에는 어떤 전문화된 과학적 계산 능력이 있는 고사양 소비자 카드로서 시작했음에도 불구하고
이 GPU 시리즈는 오랬동안 과학 계산 연구의 뿌리로 돌아가고 있습니다.
엔비디아가 분명하게 통합 드라이버 모델을 갖춘 GPU를 지원하는 동안
나는 극히 일부분의 소비자만이 접근하게 될 GPU 패밀리로부터
정교하게 조정되는 게이밍 지원을 기다리는데 숨을 죽이지는 않을 것입니다.

 중국의 경제 규제 기관이 DRAM과 NAND 가격 담합을 조사하고 있다.
중국의 경제 규제 기관이 DRAM과 NAND 가격 담합을 조사하고 있다.
 AMD가 8K 비디오를 편집할 수 있는 베가 GPU를 2사분기에 출시할 ...
AMD가 8K 비디오를 편집할 수 있는 베가 GPU를 2사분기에 출시할 ...