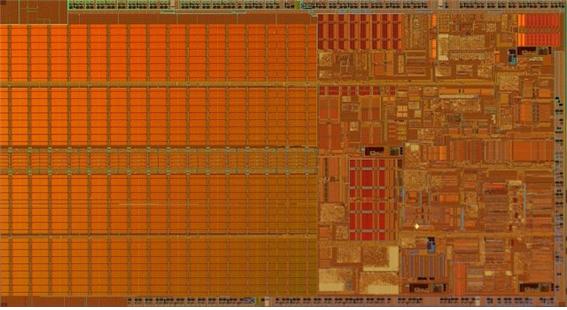
캐쉬와 캐슁의 발전은 컴퓨터 역사상 가장 중요한 사건중의 하나다.
실질적으로 초절전 칩인 ARM Cortex-A5같은 CPU에서 최고성능의 인텔 Core i7 CPU까지 캐쉬를 사용한다.
최고의 마이크로컨트롤러마저도 종종 작은캐쉬를 갖고 있거나 옵션으로 제공한다.
성능의 이점이 너무 커서 초절전 설계에서조차 무시할 수 없다.
캐슁은 중요한 문제를 해결하기 위해 고안되었다.
컴퓨터 역사의 초기 몇십년동안 메인 메모리는 너무 느리고 믿을수 없을 정도로 비쌌다.
그러나 CPU 역시 특별나게 빠르진 않았다.
1980년대에 들어서면서 아주 빨리 차이가 벌어지게 되었다. 마이크로프로세서의 클럭속도가 하늘을치솟는데 반해
메모리 접근 시간은 별로 향상되지 않았다.
그 차이가 자꾸 커지는 바람에 차이를 메우기 위해 새로운 형태의 빠른 메모리가 필요하다는 것이 점점 명백해졌다.
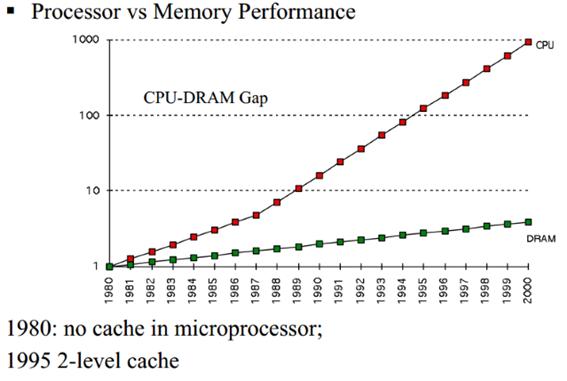
2000까지 올라가는 동안에 1980년서부터 커지는 성능차이때문에 첫 번째 캐쉬를 개발하게 되었다.
CPU 캐쉬는 작은 메모리풀로서 CPU가 다음번에 가장 필요로 하는 정보를 담는다.
어떤 정보를 캐쉬에 적재하느냐는 복잡한 알고리즘과 코드프로그래밍에 대한 특별한 가정에 의해 달려있다.
캐쉬 시스템의 목적은 CPU가 몇 비트의 다음데이타를 필요로 할 때 그 데이터를 찾으려 할때까지는
이미 캐쉬에 적재되게 만드는 것이다. (캐쉬 적중이라고 불린다.)
캐쉬 미스는 반면에 CPU가 데이터를 다른곳에서 찾느라 어려움을 격게되는 것을 의미한다.
이점 때문에 L2 캐쉬가 역할을 하게 된 것이다. 좀 더 느린반면에 좀 더 크기가 크다.
어떤 프로세서는 캐쉬 디자인이 데이터를 L1 캐쉬와 L2캐쉬 두군데에 복제해 공유해서 쓰는 데 반해
어떤 프로세서는 독점적으로 두 캐쉬가 데이터를 공유하지 않는다.
만약에 데이터가 L2캐쉬에도 없다면 CPU는 계속에서 한등급 낮은 L3(보통은 CPU에 내장되어 있다)에서
그리고 설치되어 있다면 L4와 메인메모리(DRAM)에서 계속 찾는다.
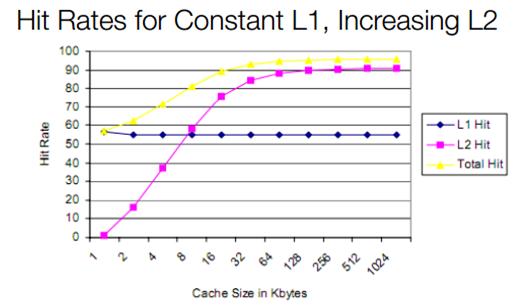
이 차트를 보면 더 큰 L2 캐쉬가 없는 일정한 캐쉬적중율을 가진 L1캐쉬 사이의 관계를 알 수 있다.
L2캐쉬의 크기가 증가함에 따라 전체 캐쉬 적중률은 아주 날카롭게 올라가는 것을 주의하라.
더 크고 더 느린 더 값싼 L2 캐쉬는 큰 L1캐쉬의 장점을 이끌어 내고있으며 다이 크기와 전력소비의 약점이 없다.
대부분의 현대 L1 캐쉬 적중률은 이론적으로 여기에서 알수 있는 50%보다는 훨씬 높다.
인텔과 AMD는 실질적으로 95% 이상의 캐쉬적중률을 가진다.
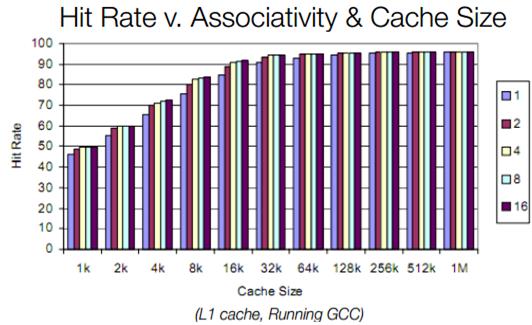
다음 중요한 주제는 set-associativity라는 것이다.
모든 CPU는 태그 RAM이라고 불리는 특별한 형태의 RAM을 가지고 있다.
태그 RAM은 어떠한 캐쉬블록에도 할당할 수 있는 메모리 위치를 기록한 것이다.
만약 캐쉬가 완전히 associative한 것이라면
그것은 어떤 RAM 데이터의 블록이라도 어떠한 캐쉬의 블록에 저장될 수 있다는 것을 의미한다.
그런 시스템의 장점은 적중률이 매우 높다는 것이다.
그러나 찾는 시간이 극단적으로 오래 걸리고 CPU는 데이터가 존재하는 지 알기위해
메인메모리를 찾기전에 모든 캐쉬를 뒤지고 다닌다는 점이다.
스펙트럼의 반대쪽에는 직접 할당할 수 있는 캐쉬가 있다.
직접 할당 캐쉬는 각각의 캐쉬가 오직 메인메모리의 한 블록만 담고 있다.
이런 형태의 캐쉬는 매우 빨리 데이터에 접근할 수 있다.
그러나 1대1로 메모리 위치를 지정하기 때문에 적중률이 낮다.
이 두 개의 극단사이에 n-way associative 캐쉬가 있다.
2-way associative 캐쉬(파일드라이버의 L1이 2-way다)는 각각의 메모리 블록을 두 개의 캐쉬블럭중 하나에 할당할
수 있다.
8-way associative 캐쉬는 메인 메모리의 블록을 각각 8개의 캐쉬블럭의 하나에 할당할 수 있다.
다음 두 개의 슬라이드 쇼는 set associativity가 적중률을 향상시키는 것을 보여준다.
적중률같은 것은 아주 특별한 경우니 다른 응용프로그램에서는 아주 다른 적중률을 가진다는 점을 기억해두라.
CPU 캐쉬가 점점 커지는 이유
그럼 왜 점점 더 큰 캐쉬를 사용하는가?
각각의 추가적인 메모리 풀 덕분에 메인메모리에 접근할 필요가 없는것이며 특정한 경우에는 성능을 향상시킬 수
있다.
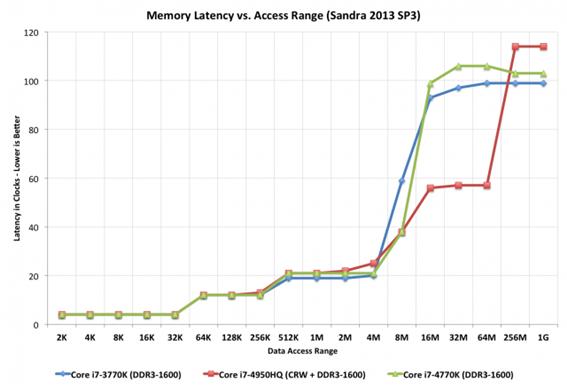
아난드테크의 하스웰 리뷰에서의 이 차트는 유용한데 전통적인 L1\L2\L3 구조뿐만 아니라
커다란 128MB L4 캐쉬를 추가하는 데에 따른 성능효과를 설명하고 있다.
붉은 색 선이 L4를 가지고 있는 CPU다. 큰 파일 크기를 주목하라. 다른 두 개의 인텔 CPU보다 거의 두배 빠르다.
그렇다면 논리적으로 보면 칩내부의 on-die의 많은 자원을 캐쉬에 사용하는 것이 타당해 보인다.
그러나 그렇게 하면 한계체감의 법칙이 있다는 것이 밝혀졌다.
더 큰 캐쉬는 또한 느리고 더 비싸다. SRAM의 한 개의 비트당 6개의 트랜지스터가 필요하다는 점에서 캐쉬는 또한
비싸다.
(다이 크기와 그러므로 비용이 든다)
어떤 점에서는 더 많은 실행유닛,더 나은 분기 예측, 또는 추가적인 코어에 CPU의 전기와 트랜지스터의 수를 사용하
는게 더 타당하다.
캐쉬 디자인이 성능에 어떻게 영향을 미치나
CPU캐쉬를 추가하는 데 성능은 효율성이나 적중률과 직접적으로 관련있다.
계속되는 캐쉬 미스는 CPU 성능에 재난적인 영향을 끼친다.
다음 예는 대체로 간단하게나마 그 점을 설명하는데 도움이 된다. 상상해 보자.
CPU가 한번에 100차례 L1캐쉬에서 데이터를 가져오려고 한다.
L1 캐쉬는 1ns 접근 지연시간이 있고 100% 적중률을 갖고 있다.
따라서 이 명령을 실행하는데 CPU는 100 나노초가 걸린다.

하스웰-E 다이 사진. CPU의 가운데에 연속적인 구조들이 공유되는 L3 캐쉬이다
자 캐쉬가 99% 적중률을 가지고 있다고 가정하자.
CPU가 100번째 접근을 해서 가져와야 할 데이터가 L2에 있는데 10ns의 접근 지연시간이 있다고 하자.
이것이 의미하는 것은 처음 99개의 데이터를 읽어서 실행하는데 99나노초가 걸리지만 10번째는 10나노초가 걸린다는 것이다.
1%의 적중률 감소가 무려 10%의 성능저하를 가져온 것이다.
실제로는 L1 캐쉬는 95%에서 97%의 적중률을 가진다.
그러나 우리의 간단한 예에서 보듯이 그 두 수치의 성능에 끼치는 영향은 2%가 아니라 14%이다.
잃어버린 데이터가 L2 캐쉬에 늘 있다고 가정한 것이다.
캐쉬에서 사라진 데이터가 메인 메모리에 있다면 접근지연시간이 80에서 120나노초가 되는데
95%와 97% 적중률사이의 성능차이는 명령어를 실행시키기 위해 필요한 총시간의 거의 두배가 된다.
AMD의 불도저가 인텔의 프로세서와 비교할 때 캐쉬디자인과 성능영향이라는 주제가 많이 쟁점이 됬다.
불도저의 낮은 성능이 상대적으로 느린 캐쉬 하부시스템과 상대적으로 높은 지연시간때문인지는 확실하지 않다.
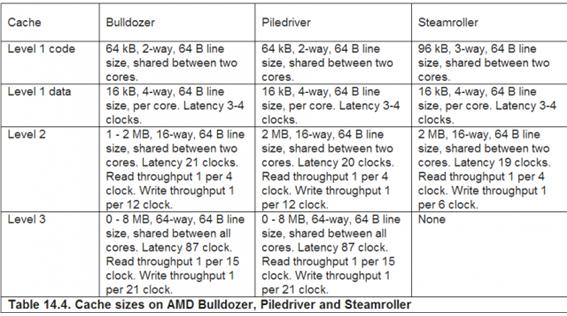
불도저 패밀리는 많은 논란이 되었다. 불도저/파일드라이버/스팀롤러는 아래에서 보다시피 L1명령어 캐쉬를 공유한
다
두 개의 다른 쓰레드가 같은 메모리 영역에 데이터를 쓰고 그리고 덮어쓸 때 캐쉬가 문제가 된다.
이 때문에 두 개의 쓰레드는 성능이 저하되는데
각각의 코어는 L1캐쉬에 우선적으로 자기 데이터를 쓰는데 시간을 소비하고
다른 하나는 즉시 그 정보를 덮어쓰게 된다. 스팀롤러는 이 문제 때문에 느려진다.
AMD가 L1 명령어 캐쉬를 96KB로 늘이고 two대신에 three-way associative로 만들어도 마찬가지다.
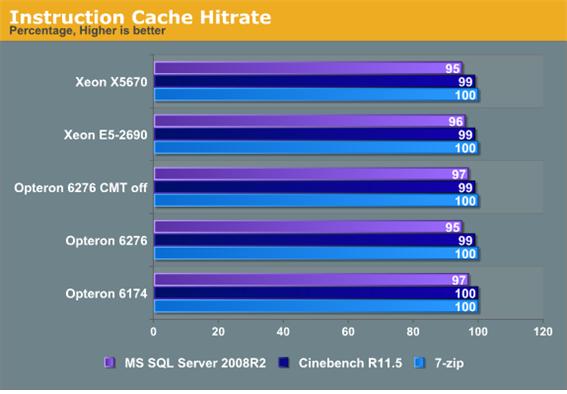
이 그래프는 옵테론 6276(원래의 불도저 프로세서)의 적중률이 두 개의 코어가 활성화되었을 때
적어도 몇 몇 테스트에서 떨어진다는 것을 보여준다.
그러나 캐쉬문제가 유일한 문제는 아닌 것이다.
6276은 언제나 6174를 성능에서 이겼는데 이때 두 프로세서는 같은 적중률을 가지고 있었다.
캐슁 아웃
이점에서 AMD 이길을 걸어갈 것이냐는 공개된 의문이다.
이 회사가 HSA와 공유 실행 자원에 강조를 두는 것을 보면 다른 길로 가는 것 같다.
그리고 AMD는 현재 비용을 치를 만한 프리미엄급을 만들려고 하지 않는 것 같다.
그럼에도 불구하고 캐쉬 설계,전력 소비,그리고 성능은 미래의 프로세서의 성능에 중요할 것이다.
현재 설계의 실질적 향상은 그것을 실행할수 있는 회사의 상태를 올려줄 것이다.

 인텔이 그들의 가상현실 HMD를 만들고 있다.
인텔이 그들의 가상현실 HMD를 만들고 있다.
 인텔의 SSD가 곧 10TB 용량을 출시한다
인텔의 SSD가 곧 10TB 용량을 출시한다