지난 주 GPU 기술 회의에서 엔비디아의 CEO인 젠슨 황은
고성능 계산 또는 우주를 목표로 한 주요한 제품과 기술을 공개했다.
여기에는 테슬라 P100 데이터 센터 가속기와
그와 짝을 이루는 DGX-1 심층 학습 시스템이 포함되어 있는데
이 시스템은 무려 8개의 테슬라 P100 카드가 장착된 강력한 서버이다.
오늘은 엔비디아의 파스칼 GPU 아키텍쳐라고 알려진
P100에서 채택된 아키텍쳐에 대한 정보를 가지고 있다.
파스칼은 엔비디아의 현재 세대의 그래픽 카드와 모바일 GPU가 사용하는
맥스웰 아키텍쳐의 후속작이다.
그리고 테슬라 P100의 중심에 있는 파스칼 기반의 GPU는
코드네임이 GP100이라고 하는데 이 제품은 아주 다른 굉장한 제품이 될 것이다.


엔비디아가 과거 차세대 제품에 이름 짓는 관행이 계속해서 유지된다면
GP100은 파스칼의 제일 높은 버전이고 추측컨대
조금 성능을 낮춘 제품이 주류 소비자 급 GPU가 될 것이다.
맥스웰의 경우 제일 높은 버전의 GM200은 GM204기반의 카드가 나올 때까지는
일반 소비자급의 GPU로는 나오지 않았다.
더 작은 맥스웰 기반의 GPU는 시장에 나온지 좀 됬다.
여러 면에서 기존 세대의 테슬라 제품을 보자.
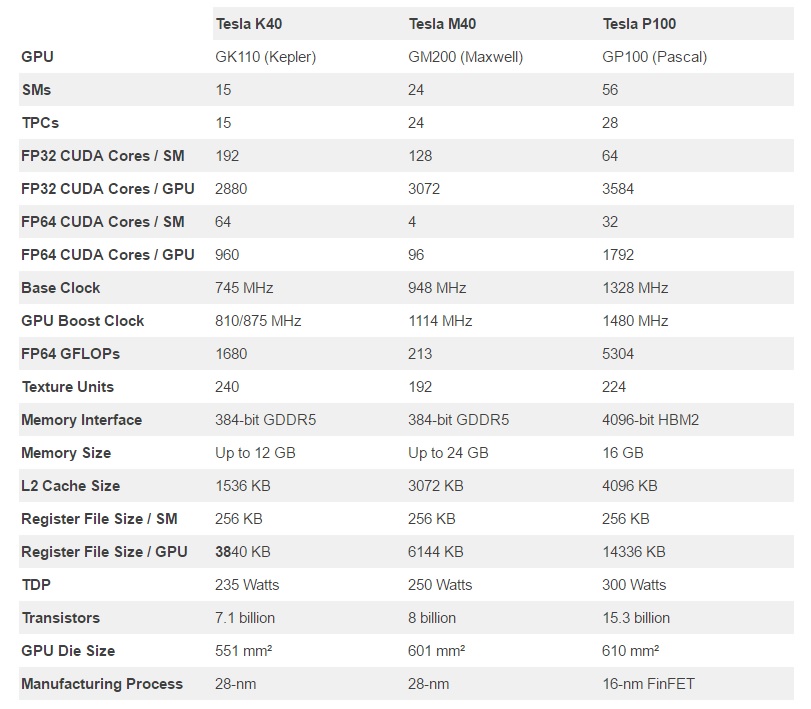
지금까지 GP100에 대해 알고 있는 바에 의하면 GP100은 완벽한 GPU 절대강자이다.
GP100은 엔비디아의 전세대 고사양 제품보다 계산 성능은 거의 세배 빠르고
GPU to GPU의 대역폭은 다섯배 넓고, 메모리 대역폭은 3배나 넓다.
현재까지 밝혀진 완전한 특징과 스펙은 위 표에 나와있다.
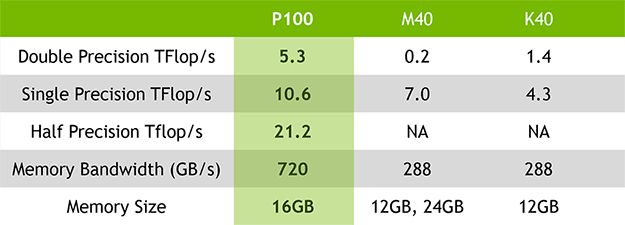
GP100은 TSMC의 16nm FinFET 공정을 이용해 만들어진다.
이 GPU는 대략 153억개의 트랜지스터로 이루어져 있고 610제곱밀리미터의 다이 크기를 가진다.
이 크기는 맥스웰 기반의 GM200의 601제곱밀리미터와 거의 같은 크기이다.
그러나 트랜지스터의 숫자는 거의 두배인 153억개 대 80억개.
발전된 생산 공정에 더해서 엔비디아의 GP100은
2세대 고대역폭 메모리를 사용하고 또 NVLink, 통합 메모리, 그리고 새로운 보드/커넥터 설계를 이용한다.

GP100은 모두 60개의 스트리밍 멀티프로세서(SM)를 가지고 있다.
그러나 테슬라 P100에서는 그 SM중 56개만 활성화되어있다.
GPU의 기본 클럭은 인상적인데 1348MHz이며
부스트 클럭은 1480MHz이고 TDP는 300와트이다.
TSMC의 16nm FinFET공정이 아직 초기인데도
이러한 높은 클럭을 볼 수있다는 것은 엔비디아에게는 좋은 징조이다.
GP100을 탑재한 테슬라 P100은 5.3테라플롭스의 더블 프레시젼 계산성능을 갖고 있다.
이것은 10.6테라플롭스의 풀 프레시젼 계산성능,
그리고 21.2 테라플롭스의 하프 프레시젼 계산을 보여준다.
또한 맥스웰에서는 사용할 수 없었지만 파스칼에서는
더블 프레시젼 계산에서 아토믹 어디션 계산이 가능하다.

GP100의 내부에는 56개의 활성화된 스트리밍 멀티프로세서에
총 3584개의 FP32 코어를 가지고 있고 이것은 1792개의 FP64 코어와 같다.
SM당 64개의 FP32/32개의 FP64코어이며 총 224개의 텍스쳐 유닛이 있다.
GPU는 16GB의 2세대 고대역폭 메모리와 4096비트의 인터페이스로 연결되어 있는데
최대 720GB/s의 대역폭을 제공한다. 칩안에는 4MB의 L2 캐쉬가 있으며
SM마다 256K의 레지스터 파일이 있어 총 14336KB에 달한다.
전 세대에 비해 레지스터는 두배이고 공유된 메모리 용량은 1.33배이고
공유되는 메모리 대역폭은 두배이다. 다른 말로 하면 이 것은 엄청난 물건이다. 좀 더 깊이 들어가 보겠다.
테슬라 P100과 GP100 GPU는 칩내부에서보다 말할 것이 더 있다.
GP100은 16GB의 CoWoS( Chip on Wafer on Substrate) 2세대 고대역폭 메모리가 특징이며
NVLink를 지원한다. 그리고 새로운 보드/커넥터 셜계를 사용한다.

2세대 고대역폭 메모리는 기본적으로 AMD의 Fury 그래픽카드에서
사용되는 1세대 고대역폭 메모리와 유사하다.
그러나 2세대 고대역폭 메모리는 데이터 레이트가 2배이고 더 큰 용량이 지원된다.
또한 시그널링을 향상시키고 에러비율을 줄이기 위해서 기술을 수정하고 향상시켰다.
엔비디아는 GP100에 있는 2세대 고대역폭 메모리에는 ECC가 없다고 한다.
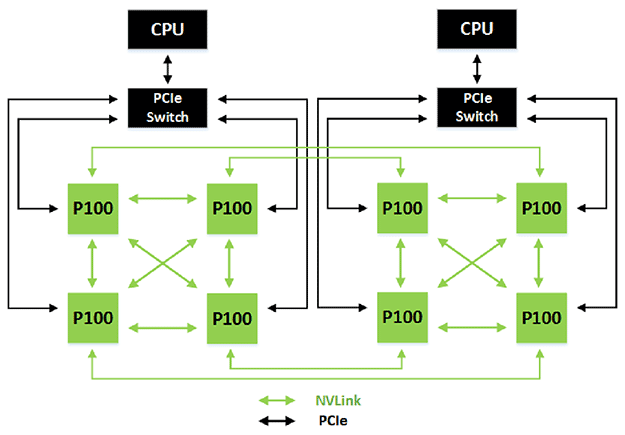
NVLink는 엔비디아가 상당한 시간동안 들여 얘기해왔다.
사실 우리는 GTC’14 취재때 이미 그것을 처음으로 언급했다.
NVLink는 GP100 GPU들 사이에서 160GB/s의 쌍방향 인터커넥터 대역폭이 가능하다.
(위의 다이아그램에서 보듯이 두 개의 완전히 연결된 쿼드 ,코너에서 연결됨)
그리고 8개에 달하는 GP100기반의 테슬라 P100 보드는 서로 연결할 수 있다.
네 개의 GP100을 싱글 쿼드에 연결시킨다면
NVLink는 peer traffic을 위해 GPU(쌍방향)당 120GB/s의 속도와
CPU와 쌍방향으로 연결된 GPU당 40GB/s의 속도를 낸다.
NVLink는 시리얼 인터커넥트 기술인데
몇 년동안 유행했던 기술인, 차별화된 ,내장된 시계와 함께 하는 시그널링을 채택했다.
그 기술은 통합된 메모리 아키텍쳐와 캐쉬일관성을 허용한다.
NVLink는 명령어 세트와 프로그래밍 모델 관점에서 PCI Express와 유사하다.
그러나 NVLink는 훨씬 많은 대역폭과 더 나은 대역폭 이용을 할 수 있다.
엔비디아는 NVLink와 함께라면 94%의 대역폭 효율성이 나온다고 주장한다.
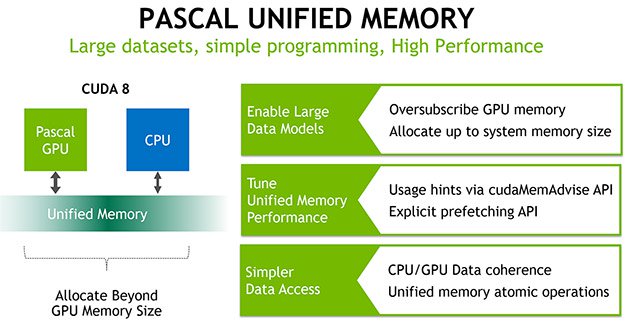
엔비디아의 파스칼의 또다른 특징은 통합메모리 아키텍쳐이다.
GPU는 가상메모리가 페이징을 요구할 때를 지원하는 페이지 마이그레이션 엔진을 갖고 있다.
그것은 49비트의 가상 주소를 사용하는데
이 주소는 모든 GPU 메모리에다가 추가적으로 48비트 CPU 주소를 커버할 수 있다.
또한 GPU 페이지 펄팅도 지원한다. 엔비디아사는 그 GPU가 수천개의 동시 페이지 펄트를 다룰 수 있다고 한다.
마지막으로 이 GPU는 2MB 페이지 크기까지 지원하고
더 나은 TLB(Translation Look-Aside Buffer)가 GPU 메모리 또한 커버할 수 있다.
케플러와 맥스웰이 통합 메모리를 지원했지만
그것들은 사용가능한 GPU 메모리의 크기와 같은 메모리 공간으로 제한되어있다.
파스칼은 제한이 없다. GP100은 GPU메모리 이상의 메모리를 할당할 수 있는데
사용가능한 모든 시스템 메모리까지 할당할 수 있다.
우리는 파스칼과 가까운 미래에 아키텍쳐를 사용할 여러 GPU에 대해 더 많이 배워야 한다.
지금은 엔비디아가 고성능컴퓨터 시장을 위해
그 손에 강력한 기본 GPU 아키텍쳐를 가지고 있는 것으로 보인다.
만약 GP100이 소비자용 생산품으로 만들어지는 것을 보게 된다면
그러나 역사가 지표라면 그것이 어떤 형태론 와서
타이탄 X가 현재 차지한 공간을 채울 것이다.
범돌컴 - 아무래도 VGA공부를 해야 할 것같습니다. 어렵습니다.

 AMD 라데온 R9 480과 라데온 R9 470 시리즈의 세부사항 –폴라리스...
AMD 라데온 R9 480과 라데온 R9 470 시리즈의 세부사항 –폴라리스...
 [간단한 루머]최신의 엔비디아 그래픽 카드의 드라이버가 GPU를 ...
[간단한 루머]최신의 엔비디아 그래픽 카드의 드라이버가 GPU를 ...